Get HTTP Header
Delve into the world of HTTP headers and enhance your understanding of web requests. Discover the significance of HTTP headers, how they influence web interactions, and how to analyze them efficiently. Our HTTP header tool provides a user-friendly platform to explore and optimize your web requests, empowering you to fine-tune your web presence for better performance and user experience.
Share on Social Media:
Whether you're a programmer or not, you've seen it everywhere on the web. Right now, your browser's address bar shows something that starts with "https://". Even your first Hello World script sent HTTP headers without you realizing it. In this article, we're going to learn the basics of HTTP headers and how we can use them in our web applications.
What are HTTP headers?

The initials HTTP stand for "Hypertext Transfer Protocol". The entire World Wide Web uses this protocol. It was established in the early 1990s. Almost everything you see in your browser is transmitted to your computer via HTTP. For example, when you open the page of this article, your browser has probably sent more than 40 HTTP requests and received HTTP responses for each one.
HTTP headers are the core part of those HTTP requests and responses, and they carry information about the client browser, the requested page, the server, and more.
Example When you type a URL in the address bar, your browser sends an HTTP request, and it might look like this:
| 1 | GET /tutorials/other/top-20-mysql-best-practices/ HTTP/1.1 |
| 2 | Host: net.tutsplus.com |
| 3 | User-Agent: Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.5) Gecko/20091102 Firefox/3.5.5 (.NET CLR 3.5.30729) |
| 4 | Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 |
| 5 | Accept-Language: en-us,en;q=0.5 |
| 6 | Accept-Encoding: gzip,deflate |
| 7 | Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7 |
| 8 | Keep-Alive: 300 |
| 9 | Connection: keep-alive |
| 10 | Cookie: PHPSESSID=r2t5uvjq435r4q7ib3vtdjq120 |
| 11 | Pragma: no-cache |
| 12 | Cache-Control: no-cache |
The first line is the "Request Line," which contains some basic information about the request. And the rest are HTTP headers.
After that request, the browser receives an HTTP response, which may look like the following:
| 1 | HTTP/1.x 200 OK |
| 2 | Transfer-Encoding: chunked |
| 3 | Date: Sat, 28 Nov 2009 04:36:25 GMT |
| 4 | Server: LiteSpeed |
| 5 | Connection: close |
| 6 | X-Powered-By: W3 Total Cache/0.8 |
| 7 | Pragma: public |
| 8 | Expires: Sat, 28 Nov 2009 05:36:25 GMT |
| 9 | Etag: "pub1259380237;gz" |
| 10 | Cache-Control: max-age=3600, public |
| 11 | Content-Type: text/html; charset=UTF-8 |
| 12 | Last-Modified: Sat, 28 Nov 2009 03:50:37 GMT |
| 13 | X-Pingback: https://net.tutsplus.com/xmlrpc.php |
| 14 | Content-Encoding: gzip |
| 15 | Vary: Accept-Encoding, Cookie, User-Agent |
| 16 | |
| 17 | <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> |
| 18 | <html xmlns="http://www.w3.org/1999/xhtml"> |
| 19 | <head> |
| 20 | <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> |
| 21 | <title>Top 20+ MySQL Best Practices - Nettuts+</title> |
| 22 | <!-- ... rest of the html ... --> |
The first line is the "Status Line," followed by "HTTP Headers," up to the blank line. After that, the "content" begins (in this case, an HTML output).
When you view the source code of a web page in your browser, you will only see the HTML portion and not the HTTP headers, even though they have actually been transmitted together as you can see above.
Those HTTP requests are also sent and received for other things, such as images, CSS files, JavaScript files, etc. That's why I said earlier that your browser has sent at least 40 or more HTTP requests while loading just the page of this article.
Now, let's delve into the structure in more detail.
How to View HTTP Headers I use the following extension for Firefox to analyze HTTP headers:
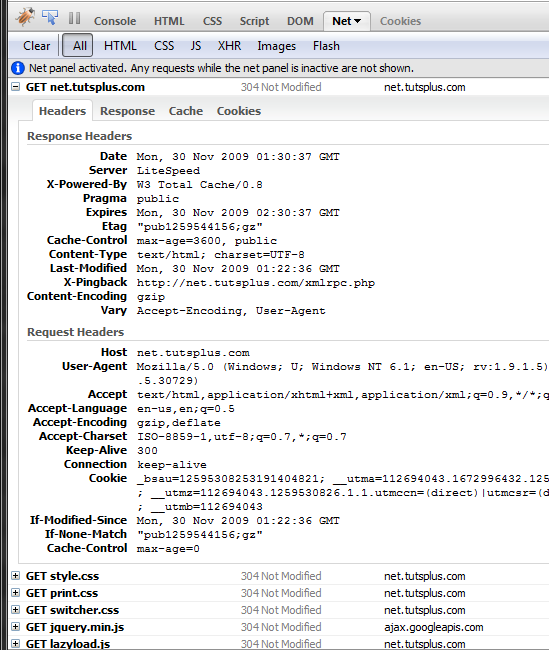
HTTP Request Structure
The first line of the HTTP request is called the request line and consists of 3 parts:
The "verb" indicates what type of request this is. The most common verbs are GET, POST, and HEAD. The "path" is usually the part of the URL that comes after the domain. For example, when requesting "https://net.tutsplus.com/tutorials/other/top-20-mysql-best-practices/", the path portion is "/tutorials/other/top-20-mysql-best-practices/". The "protocol" part contains "HTTP" and the version, which is usually 1.1 in modern browsers. The rest of the request contains HTTP headers as "Name: Value" pairs on each line. They contain various information about the HTTP request and your browser. For example, the "User-Agent" line provides information about the browser version and operating system you are using. "Accept-Encoding" tells the server whether your browser can accept compressed output like gzip.
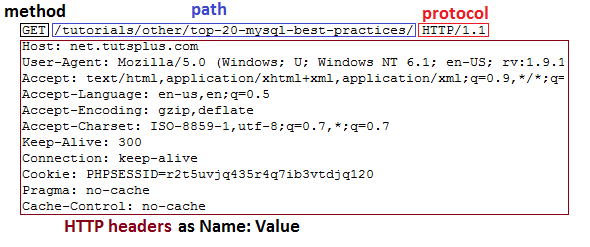
You may have noticed that cookie data is also transmitted within an HTTP header. And if there were a referring URL, it would be in the header as well.
Most of these headers are optional. This HTTP request could have been as small as this:
GET /tutorials/other/top-20-mysql-best-practices/ HTTP/1.1 Host: net.tutsplus.com And yet you would still have received a valid response from the web server.
Request Methods The three most common request methods are: GET, POST, and HEAD. You're probably already familiar with the first two, from writing HTML forms.
GET: Retrieve a Document This is the primary method used to retrieve HTML, images, JavaScript, CSS, etc. Most of the information loaded into your browser has been requested using this method.
For example, when you load an article from Nettuts+, the first line of the HTTP request looks like this:
| 1 | GET /tutorials/other/top-20-mysql-best-practices/ HTTP/1.1 |
| 2 | Host: net.tutsplus.com |
And yet you would still have received a valid response from the web server.
Request Methods The three most common request methods are: GET, POST, and HEAD. You're probably already familiar with the first two, from writing HTML forms.
GET: Retrieve a Document This is the primary method used to retrieve HTML, images, JavaScript, CSS, etc. Most of the information loaded into your browser has been requested using this method.
For example, when you load an article from Nettuts+, the first line of the HTTP request looks like this:
| 1 | GET /tutorials/other/top-20-mysql-best-practices/ HTTP/1.1 |
| 2 | ... |
Once the HTML loads, the browser will start sending GET requests for images, which can be seen as follows:
| 1 | GET /wp-content/themes/tuts_theme/images/header_bg_tall.png HTTP/1.1 |
| 2 | ... |
Web forms can be configured to use the GET method. Here's an example.
| 1 | <form method="GET" action="foo.php"> |
| 2 | |
| 3 | First Name: <input type="text" name="first_name" /> <br /> |
| 4 | Last Name: <input type="text" name="last_name" /> <br /> |
| 5 | |
| 6 | <input type="submit" name="action" value="Submit" /> |
| 7 | |
| 8 | </form> |
When the form is submitted, the HTTP request starts like this:
| 1 | GET /foo.php?first_name=John&last_name=Doe&action=Submit HTTP/1.1 |
| 2 | ... |
Even though you can send data to the server using GET and the query string, in many cases POST would be preferable. Sending large amounts of data using GET is not practical and has its limitations.
POST requests are more commonly sent by web forms. Let's change the previous example form to use the POST method.
| 1 | <form method="POST" action="foo.php"> |
| 2 | |
| 3 | First Name: <input type="text" name="first_name" /> <br /> |
| 4 | Last Name: <input type="text" name="last_name" /> <br /> |
| 5 | |
| 6 | <input type="submit" name="action" value="Submit" /> |
| 7 | |
| 8 | </form> |
Upon submitting that form, an HTTP request is created like this:
| POST /foo.php HTTP/1.1 | |
| 2 | Host: localhost |
| 3 | User-Agent: Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.5) Gecko/20091102 Firefox/3.5.5 (.NET CLR 3.5.30729) |
| 4 | Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 |
| 5 | Accept-Language: en-us,en;q=0.5 |
| 6 | Accept-Encoding: gzip,deflate |
| 7 | Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7 |
| 8 | Keep-Alive: 300 |
| 9 | Connection: keep-alive |
| 10 | Referer: http://localhost/test.php |
| 11 | Content-Type: application/x-www-form-urlencoded |
| 12 | Content-Length: 43 |
| 13 | |
| 14 | first_name=John&last_name=Doe&action=Submit |
There are 3 important things to note here:
The path in the first line is simply /foo.php and there is no longer a query string. The Content-Type and Content-Length headers have been added, which provide information about the data being sent. All data is now sent after the headers, in the same format as the query string. POST method requests can also be made via AJAX, applications, cURL, etc. And all file upload forms require the use of the POST method.
HEAD: Retrieve Header Information HEAD is identical to GET, except that the server does not return the content in the HTTP response. When you send a HEAD request, it means you are only interested in the response code and HTTP headers, not the document itself.
"When you send a HEAD request, it means you are only interested in the response code and HTTP headers, not the document itself."
With this method, the browser can check if a document has been modified, for caching purposes. It can also check if the document definitely exists.
For example, if you have a lot of links on your website, you can periodically send HEAD requests to all of them to check for broken links. That will work much faster than using GET.
HTTP Response Structure
After the browser sends an HTTP request, the server responds with an HTTP response. Excluding the content, it looks like this:
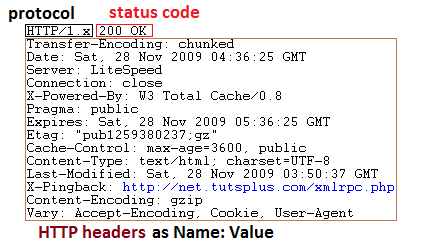
The first piece of data is the protocol. This is again usually HTTP/1.x or HTTP/1.1 on modern servers.
The next part is the status code followed by a short message. Code 200 means that our GET request was successful and the server will return the contents of the requested document, just after the headers.
We've all seen "404" pages. This number actually comes from the status code part of the HTTP response. If the GET request was made for a route that the server cannot find, it would respond with a 404 instead of a 200.
The rest of the response contains headers like the HTTP request. These values can contain information about the server software, when the page/file was last modified, the MIME type, etc…
Again, most of these headers are actually optional.
HTTP Status Codes 200 are used for successful requests. 300 are for redirections. 400 are used if there was some issue with the request. 500 are used if there was some issue with the server.
200 OK
As mentioned earlier, this status code is sent in response to a successful request.
206 Partial Content
If an application requests only a range of the requested file, the 206 code is returned.
It is most commonly used with download managers that can pause and resume a download, or split the download into pieces.
404 Not Found
When the requested page or file is not found, a 404 response is sent by the server.
401 Unauthorized
Password-protected web pages send this code. If you don't enter a correct login, you may see the following in your browser.
Please note that this only applies to HTTP password-protected pages that display pop-up windows like the following to log in.
403 Forbidden
If you're not allowed to access the page, this code may be sent to your browser. This often happens when you try to open the URL of a folder that doesn't contain an index page. If the server configuration doesn't allow displaying the contents of the folder, you'll get a 403 error.
For example, on my local server, I created an images folder. Inside this folder, I put a .htaccess file with this line: "Options - Indexes". Now when I try to open http://localhost/images/ - I see this.
There are other ways in which access can be blocked, and a 403 may be sent. For example, you can block by IP address, with the help of some htaccess directives.
302 (or 307) Found & 301
Moved Permanently These two codes are used to redirect the browser. For example, when you use a URL shortener server like bit.ly, this is exactly how they redirect people who click on their links.
Both 302 and 301 are handled very similarly by the browser, but they may have different meanings for search engine spiders. For example, if your website is down for maintenance, you can redirect elsewhere using 302. The search engine spider will continue to check your page later in the future. But if you redirect using 301, it will tell the spider that your website has been moved to that permanent location.
500 Internal Server Error
This code is usually seen when a web script breaks. Most CGI scripts don't display errors directly to the browser, unlike PHP. If there are some fatal errors, a 500 status code will simply be sent. And the programmer then needs to look up the server error logs to find the error messages.
Other very useful tools for SEO:
- Website Screenshot Generator
- Online HTML Viewer
- WordPress Theme Detector
- Htaccess Redirect
- Mobile Friendly Test
- Adsense Calculator
- Screen Resolution Simulator
- Twitter Card Generator
- Open Graph Generator
- Xml Formatter
- HTML Minifier
- Javascript Minifier
- CSS Minifier
- Online Ping Website Tool
- URL Opener
- URL Encoder Decoder
- Base64 Encode Decode
- QR Code Generator
- XML Sitemap Generator
- HTML Editor
- Bulk Email Validator